Product Launchmodel aware routinggkevertex aigpu utilization
Google Cloud Optimizes Vertex AI Inference Routing
8.2
Relevance Score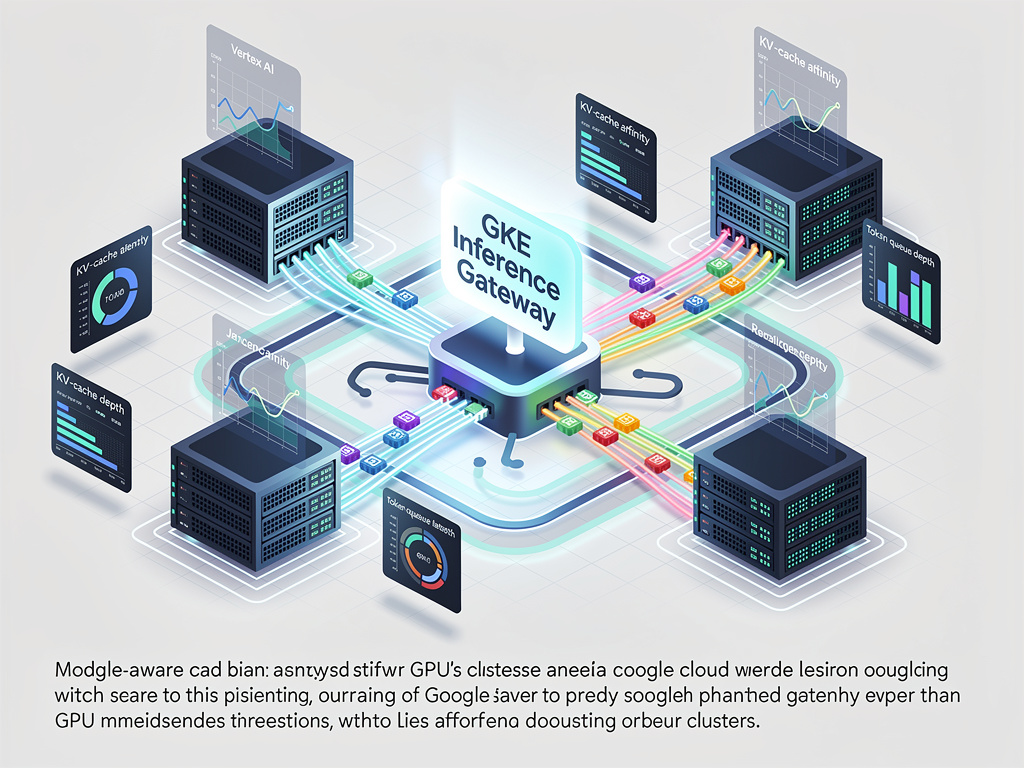
Google Cloud recently integrated a model-aware GKE Inference Gateway into Vertex AI’s serving stack to optimize LLM inference routing. The gateway inspects request cost and backend metrics to reduce head-of-line blocking, lowering P95/P99 latency and improving GPU utilization across thousands of accelerators. These improvements yield better latency for real-time applications and lower per-query infrastructure costs, supporting broader deployment across Vertex AI’s production serving fleet.


